728x90
반응형
Kafka 정의
- Distributed commit log
- 데이터를 지속해서 저장하고 읽을 수 있으며 확장에 따른 성능 저하를 방지하여 데이터가 분산 처리될 수 있다.

메시지 발행과 구독
- publish/subscribe 관계로 데이터 발행자가 발행/구독 시스템에 전송하면 구독자가 특정 부류의 메시지를 구독할 수 있도록 함
- 메시지를 저장하고 중계하는 역할은 브로커가 수행
- 메시지 발행 시스템에서즌 데이터 발행자가 직접 구독자에게 보내지 않는다!
초기의 발행/구독 시스템
- 발행자와 구독자가 직접연결된 시스템에서 발전하여
- 중간 브로커(서버)를 둔 아키텍쳐가 만들어졌다.
- 모든 애플리케이션의 메트릭을 하나의 애플리케이션이 수신하고, 하나의 서버로 제공하여 해당 메트릭이 필요한 어떤 시스템에서도 쉽게 조회 가능
카프카 사용 이유
- 중앙화된 전송 영역이 없어 end to end 연결이 복잡해진다
- 데이터 파이프라인 관리가 어려워지고
- 연결 시스템마다 다른 방식으로 구현 수 있다
메시지와 배치
- 데이터의 기본단위: 메시지
- 바이트 배열의 데이터로 특정 형식이나 의미를 갖지 않음
- 카프카 메시지 데이터는 topic으로 분류된 partition에 수록되는데 이때 데이터를 수록할 파티션을 결정하기 위해 일관된 해시 값으로 키를 생성한다.
- 카프카는 메시지가 생길때마다 보내는 게 아닌 효율성을 위해 모아 전송하는 형태의 배치로 파티션에 전송할 수 있다.
- 배치의 크기가 증가하면 → 단위 시간당 처리되는 메시지 양이 증가하지만 메시지의 전송 시간도 증가함
스키마
- 메시지의 구조를 나타내는 스키마를 사용
- Json / XML 등을 사용
- 스키마 버전 간의 호환성이 떨어져 아파치 Avro를 많이 사용(Apache에서 만듦)
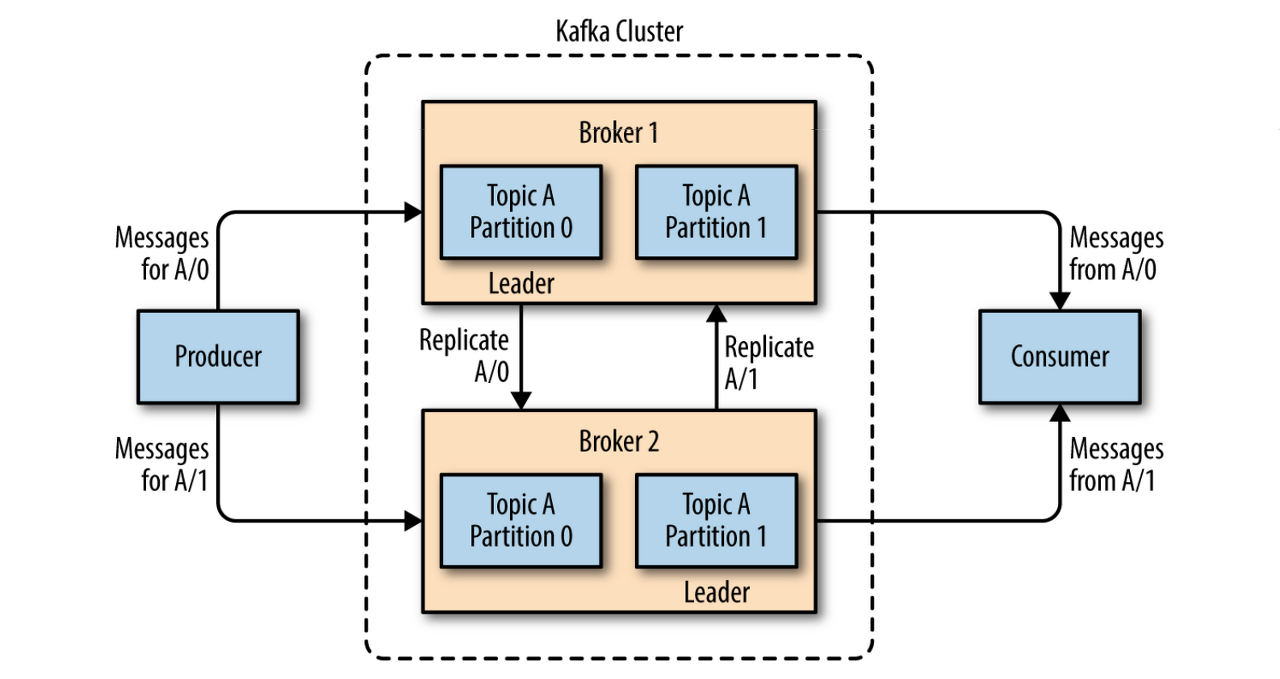
토픽과 파티션
- 카프카의 메시지는 토픽(topic)으로 분류하며 토픽은 DB의 테이블이나 파일 시스템의 폴더와 유사
- 하나의 토픽은 여러개의 파티션(partition)으로 구성됨
- 메시지는 파티션에 추가되는 형태로만 수록
- 맨 앞부터 끝까지 순서대로 읽힌다
- 메시지의 처리 순서는 토픽이 아닌 파티션 별로 유지 관리
- 각 타피션은 서로 다른 서버에 분산되어 단일 서버로 처리할 때보다 훨씬 성능이 우수하다.

프로듀서와 컨슈머
- 데이터를 쓰는 프로듀서(producer) - 데이터를 읽는 컨슈머(consumer)
- 오프라인으로 대량의 데이터를 처리하도록 설계된 프레임워크인 하둡의 방법과 대비된다.
- 프로듀서: 새로운 메시지를 생성하며 메시지는 특정 토픽으로 생성되고 기본적으로 메시지가 어떤 파티션에 수록되는지는 관여하지 않음
- 프로듀서가 특정 파티션에 메시지를 직접 쓰는 경우가 있음 - 파티셔너 사용(키의 해시 값을 생성하고 그것을 특정 파티션에 대응시켜 지정된 키를 갖는 메시지가 항상 같은 파티션에 수록되게 함)
- 컨슈머: 메시지를 읽는 주체
- 하나 이상의 토픽을 구독하여 메시지가 생성된 순서대로 읽는다.
- 메시지의 오프셋을 유지하여 메시지의 읽는 위치를 알 수 있다.
- 오프셋은 지속적으로 증가하는 정수값이며 메시지가 생성될 때 카프카가 추가해준다.
- 파티션에 수록된 각 메시지는 고유한 오프셋을 갖는다.
- 주키퍼나 카프카에서는 각 파티션에서 마지막에 읽은 메시지의 오프셋을 저장하고 있으므로 컨슈머가 메시지 읽기를 중단했다 다시 시작해도 언제든 다음부터 읽을 수 있다.
- 컨슈머는 컨슈머 그룹의 멤버로 동작
- 한 토픽을 소비하기 위해 같은 그룹의 여러 컨슈머가 함께 동작
- 한 토픽의 각 파티션은 하나의 컨슈머만 소비할 수 있다.
- 한 컨슈머가 자신의 파티션 메시지를 읽는데 실패해도 같은 그룹의 다른 컨슈머가 파티션 소유권을 재조명받고 실패한 컨슈머의 파티션 메시지를 대신 읽을 수 있다.
브로커와 클러스터
- 브로커: 하나의 카프카 서버
- 프로듀서로부터 메시지를 수신하고 오프셋을 저장한 후 해당 메시지를 디스크에 저장
- 클러스터의 일부로 동작하도록 설계되었다
- 컨트롤러의 기능을 수행
- 각 타피션은 클러스터의 한 브로커가 소유하며, 그 브로커를 파티션 리더라고 한다.
- 일정 기간 메시지를 보존하는 기능도 있다
- 각 파티션을 사용하는 모든 컨슈머와 프로듀서는 파티션 리더에 연결해야 한다.
- 다중 클러스터
- 데이터 타입에 따라 구분 및 처리
- 요구사항에 따라 분리 처리
- 다중 데이터 센터 처리
- 다중 클러스터를 지원하기 위해 미러 메이커를 사용한다.
카프카를 사용하는 이유
- 다중 프로듀서, 컨슈머
- 다중 프로듀서, 컨슈머가 상호 간섭 없이 어떤 메시지 스트림도 읽을 수 있다.
- 디스크 기반 보존
- 메시지를 보존할 수 있어 컨슈머를 항상 실시간 실행시키지 않아도 된다.
- 처리가 느리거나 접속이 폴주해서 메시지 읽는데 실패해도 데이터가 유실될 위험이 적다
- 확장성
- 브로커 1대부터 시작하여 규모에 따라 브로커를 수백대로 증가시키기고 대규모 클러스터로 묶어 사용할 수 있다.
- 동시에 여러 브로커에 장애가 생겨도 복제 팩터를 더 큰 값으로 했다면 대응할 수 있다.
이용 사례
- 활동 추적
- 메시지 전송(메일, 푸시 알림)
- 메트릭 로깅
- 커밋 로그
- 스트림 프로세싱
728x90
반응형
'코딩해 > Kafka, Spark, Data Engineering' 카테고리의 다른 글
| [Spark-submit] Console 로그 설정 | Log level (0) | 2022.06.03 |
|---|---|
| [Spark] spark.driver.maxResultSize 에러 (0) | 2022.05.11 |
| [Kafka] 카프카 파티션 | 순서 (0) | 2022.03.31 |
| [Kafka] 카프카 Kafka Rebalancing (0) | 2022.03.29 |
| [Apache Airflow] 에어플로우 | 아파치 에어플로우 기본 (0) | 2021.04.12 |
