7장 트랜잭션 정리
데이터 시스템에서 생길 수 있는 문제
- 데이터베이스 소프트웨어나 하드웨어는 쓰기 연산이 실행중일 때를 포함해서 언제라도 실패할 수 있다.
- 애플리케이션은 연속된 연산이 실행되는 도중도 포함해서 언제라도 죽을 수 있다.
- 네트워크가 끊기면 애플리케이션과 데이터베이스의 연결이 갑자기 끊기거나 데이터베이스 노드 사이의 통신이 안 될 수 있다.
- 여러 클라이언트가 동시에 데이터베이스에 쓰기를 실행해서 다른 클라이언트가 쓴 내용을 덮어쓸 수 있다.
- 클라이언트가 부분적으로만 갱신돼서 비정상적인 데이터를 읽을 수 있다.
- 클라이언트 사이의 경쟁 조건은 예측하지 못한 버그를 유발할 수 있다.
시스템이 신뢰성을 지니려면 이런 결함을 처리해서 전체 시스템의 치명적 장애로 이어지는 것을 막아야 한다.
트랜잭션은 애플리케이션에서 몇 개의 읽기와 쓰기를 하나의 논리적 단위로 묶는 방법이다. 개념적으로 한 트랜잭션 내의 모든 읽기와 쓰기는 한 연산으로 실행되며, 전체가 성공(커밋)하거나 실패(롤백)한다.
트랜잭션 실패시 애플리케이션에서 안전하게 재시도할 수 있다.
트랜잭션은 자연 법칙이 아니며, 프로그래밍 모델을 단순화 하기 위해 만든 것이다.
모든 애플리케이션에서 트랜잭션이 필요하지는 않으며 때로는 트랜잭션적인 보장을 완화하거나 아예 쓰지 않는 게 이득이다.
-> 트랜잭션이 제공하는 안전성 보장에는 어떤 것이 있으며 이와 관련된 비용이 어떻게 되는지 정확히 이해하고 사용하여야 한다.
이번 장에서 배울 점
- 문제가 생길 수 있는 여러 예를 조사하고 이런 문제를 방지하기 위해 데이터베이스에서 사용하는 알고리즘을 살펴본다.
- 동시성 제어 분야를 깊게 다룬다.
- 다양한 종류의 경쟁 조건과 데이터베이스에서 read committed, snapthop isolation, serializability와 같은 격리 수준을 어떻게 구현하는지 설명한다.
- 단일 노드 데이터베이스와 분산 데이터베이스에 모두 적용되며 분산 시스템에서만 생기는 특정 난제는 8장에서 다룬다.
ACID의 의미
1983년 데이터베이스에서 내결함성 메커니즘을 나타내는 정확한 용어를 확립하기 위해 ACID를 만들었다. 하지만 그 뜻은 모호하며, 데이터베이스마다 ACID 세부 구현은 완전히 다른다.
- Atimicity - 원자성: 여러 변경을 적용하는 도중 오류가 발생했을 때, 어보트되고 해당 트랜잭션에서 기록한 모든 내용을 취소한다는 보장이다. 안전한 재시도가 가능하다. (Abortability가 더 나은 단어)
- Consistency - 일관성: 데이터가 항상 진실인 불변식(invariant)을 만족한다는 보장이다. 데이터의 유효성 및 애플리케이션의 정책적인 측면과 관련 있으며, ACID 중 유일하게 애플리케이션의 책임이다. (예를 들면 회계 프로그램에서 차변과 대변이 항상 같아야 한다는 정책) 데이터베이스는 불변식을 위반하는 잘못된 데이터를 쓰지 못하게 막을 수 없다. 단 Foreign Key, Unique 등은 데이터베이스에서 보장한다.)
- Isolation - 격리성: 여러 트랜잭션이 동시에 같은 레코드에 접근하면 동시성 문제(경쟁 조건)이 생긴다. 이를 해결하기 위해 동시에 실행되는 트랜잭션은 서로 격리된다는 보장이 격리성이다. 트랜잭션은 다른 트랜잭션을 방해할 수 없다.
- 이는 직렬성 격리와 스냅숏 결리로 구현된다.
- 직렬성 격리(Serializable Isolation) - 동시에 트랜잭션이 실행되었어도, 순차적으로 실행되었을 때의 결과와 동일하도록 보장한다. 성능 손해가 있기 때문에 Real world에서는 거의 사용되지 않는다.
- 스냅숏 격리(Snapshot Isolation) - MVCC 등으로 구현한다.
- 이는 직렬성 격리와 스냅숏 결리로 구현된다.
- Durability - 지속성: 트랜잭션 커밋이 성공했다면 하드웨어 결함이 발생하거나 데이터베이스가 죽어도 데이터가 손실되지 않는다는 보장이다. write-ahead log, 복제, 백업 등을 통해 구현한다. 지속성을 보장하려면 데이터베이스는 트랜잭션 커밋을 보고하기 전에 쓰기나 복제가 완료될 때까지 기다려야 한다. (6장에서 다뤘듯 완벽한 지속성은 존재하지 않는다.)
단일 객체 연산관 다중 객체 연산
- ACID에서 원자성과 격리성은 클라이언트가 한 트랜잭션 내에서 여러 번의 쓰기를 하면 데이터베이스가 어떻게 해야 하는지를 서술한다.
우편함 예시
더티 읽기 - 커밋되지 않은 데이터를 읽음

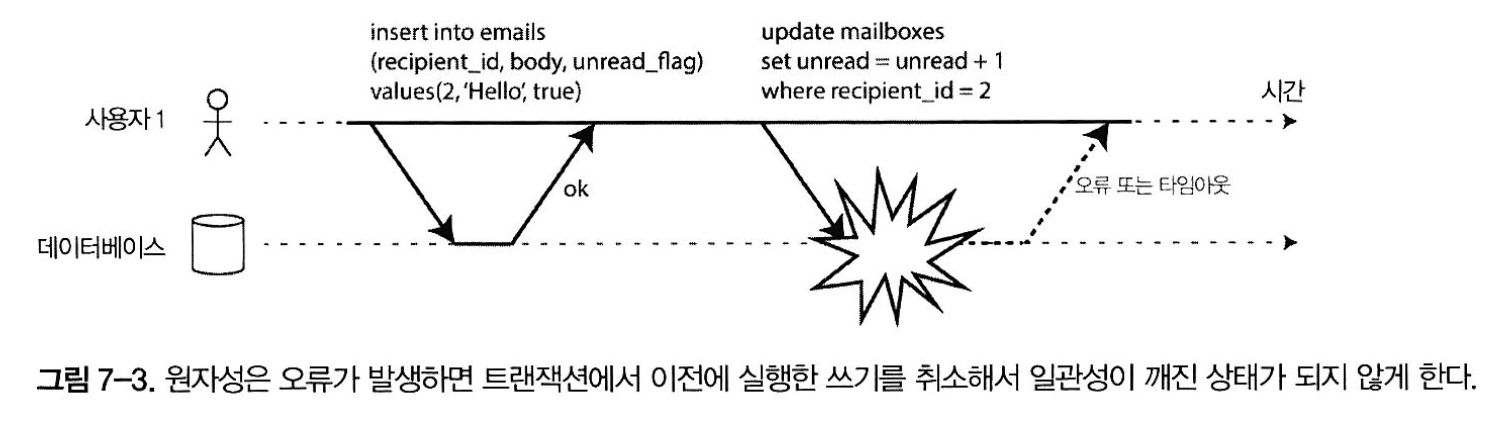
- 원자적 트랜잭선에서는 개수 갱신을 실패하면 트랜잭션이 어보트되고 삽입된 이메일은 롤백된다.
- 다중 객체 트랜잭션은 어떤 읽기 연산과 쓰기 연산이 동일한 트랜잭션에 속하는지 알아낼 수단이 있어야 한다
- 관계형 데이터베이스 - BEGIN TRANSACTION, COMMIT 사이의 모든 것은 같은 트랜잭션으로 여겨진다.
- 비관계형 데이터베이스 - 연산을 묶을 방법이 없는 경우가 많다. 어떤 키에 대한 연산은 성공하고 나머지 키에 대한 연산은 실패해서 데이터베이스가 부분적으로 갱신된 상태가 될 수 있다.
단일 객체 쓰기
- 원자성과 격리성은 단일 객체를 변경하는 경우에도 적용된다.
어떤 데이터베이스는 좀 더 복잡한 원자적 연산을 제공하기도 한다.
- 증가 연산 - read-modify-write 주기를 반복할 필요를 없앤다. (그림 7-1)
- compare-and-set 연산 - 변경하려는 값이 누군가에 의해 동시에 바뀌지 않았을 때만 쓰기가 반영되도록 허용

이런 단일 객체 연산은 여러 클라이언트에서 동시에 같은 객체에 쓰려고 할 때 갱신 손실을 방지하므로 유용하지만 일반적으로 쓰이는 의미의 트랜잭션은 아니다.
다중 객체 트랜잭션의 필요성
많은 분산 시스템에서 다중 객체 트랜잭션 지원을 포기했다. 가용성, 성능 등을 고려하여 근본적으로 트랜잭션을 막는 것은 아무것도 없기 때문이다. 9장에서 분산 트랜잭션의 구현에 대해 살펴본다.
그런데 정말 필요할까? 키-값 데이터 모델과 단일 객체 연산만 사용해서 애플리케이션을 구현하는게 가능할까? 필요하긴 하다.
트랜잭션이 없더라도 다중 객체에 실행되는 쓰기작업 등을 구현할 수 있다. 하지만 원자성이 없으면 오류 처리가 복잡해지고 격리성이 없으면 동시성 문제가 발생할 수 있다. -> "완화된 격리 수준" 에서 다루며 12장에서 대안적인 접근법을 알아본다.
오류와 어보트 처리
어보트 - 트랜잭션의 핵심 기능. 오류가 생기면 어보트 되고 안전하게 재시도할 수 있다.
리더없는 복제(179p) 데이터스토어는 best-effort 원칙으로, 오류가 발생하면 이미 한 일은 취소하지 않는다. 애플리케이션에서 오류 처리를 해야한다.
Rails의 액티브레코드, Django ORM 등은 어보트된 트랜잭션을 재시도하지 않는다. 어보트의 취지는 안전하게 재시도를 할 수 있는 것인데 말이다. (어보트된 트랜잭션을 재시도하는 것은 간단하고 효과적인 오류 처리 메커니즘이지만 완벽하지는 않기 때문.)
완화된 격리 수준
동시성 문제(경쟁 조건)은 트랜잭션이 동시에 같은 데이터를 변경하거나 동시에 변경된 데이터를 읽으려고 할 때만 나타난다.
- 테스트로 발견되기 어려워 재현하기 어렵다. (타이밍에 운이 없을 때 촉발됨)
- 추론하기도 매우 어렵다.
배울점 - 완화된 격리 수준을 몇 가지 살펴보고 발생할 수 있는 경쟁 조건과 발생할 수 없는 경쟁 조건을 설명한다. 그 후 직렬성에 대해 상세히 살펴본다.
커밋 후 읽기
- 가장 기본적인 수준의 트랜잭션 격리
1. 더티 읽기 방지
- 데이터베이스에서 읽을 때 커밋된 데이터만 보게된다.
필요한 이유: 부분적으로 갱신된 상태의 데이터베이스를 보면 혼란스러우며 다른 트랜잭션이 잘못된 결정을 하게 된다. 또한 롤백을 생각하면 머리가 아프다.

2. 더티 쓰기 방지
- 데이터베이스에 쓸 때 커밋된 데이터만 덮어쓰게 된다. 즉 먼저 수행된 트랜잭션이 데이터를 썼지만, 나중에 수행된 트랜잭션이 이를 덮어써서 커밋하는 것.
해결: 먼저 쓴 트랜잭션이 커밋이나 어보트될 때까지 두 번째 쓰기를 지연시킨다. 지연을 위해 락을 잡는다.

3. 커밋 후 읽기 구현
트랜잭션에서 틀정 객체(로우나 문서)를 변경하고 싶다면 먼저 해당 객체에 대한 잠금을 획득해야 한다.
그리고 트랜잭션이 커밋되거나 어보트될 때까지 잠금을 보유하고 있어야 한다.
그러나 이 잠금 대기 때문에 애플리케이션 일부에서 발생한 지연이 애플리케이션의 완전히 다른 부분에 연쇄 효과를 미칠 수 있다.
그림 7-4의 방법을 통한 더티 읽기를 방지하여 해당 트랜잭션이 실행 중인 동안 그 객체를 읽는 다른 트랜잭션들은 과거의 값을 읽게 된다. 새 값이 커밋되어야만 다른 트랜잭션들이 새 값을 읽을 수 있다.
스냅숏 격리와 반복 읽기
커밋 후 읽기를 사용할 때 발생할 수 있는 문제:

이런 현상을 비반복 읽기(nonrepeatable read)나 읽기 스큐(read skew)라고 한다.
스큐: '핫스팟이 생긴 블균형적인 작업부하'의 의미도 있지만 여기서는 '시간적인 이상 현상'을 말한다.
더티 읽기가 아닌 정상적인 프로세스임에도, 시간 차이로 발생하는 이상 현상
해당 케이스는 새로고침하면 별 문제가 없지만 백업이나 분석, 무결성 확인 워크로드에서는 크리티컬할 수 있다.
snapshot isolation을 통해 문제를 막을 수 있다.
- 각 트랜잭션은 데이터베이스의 일관된 스냅숏으로부터 읽는다.
- 즉 트랜잭션은 시작할 때 데이터베이스에서 커밋된 상태였던 모든 데이터를 본다.
스냅숏 격리 구현
- 쓰기를 실행하는 트랜잭션은 같은 객체에 쓰는 다른 트랜잭션의 진행을 차단할 수 있음
- 트랜잭션 작업을 시작할 때 데이터베이스의 특정 스냅숏으로부터 데이터를 읽는다.
- 핵심 원리: 읽는 작업과 쓰는 작업은 서로를 결코 차단하지 않는다. (쓰기 작업은 쓰기 작업만 차단하면 된다.)
- 데이터베이스가 객체의 여러 버전을 함께 유지하므로 이 기법은 다중 버전 동시성 제어(MVCC)라고 한다.

- tid를 통해 어떤 것을 볼 수 있고 어떤 것을 볼 수 없는지를 결정한다. -> tid12는 tid13이 계좌2에서 돈을 빼간걸 못본다는 것.
스냅숏 격리는 유용한 격리 수준이며 특히 읽기 전용 트랜잭션에 유용하다. (쓰기 잠금 + MVCC)
- mySQL, postgreSQL 에서는 repeatable read(반복 읽기) 라고 말하며
- 오라클에서는 직렬성 이라고 한다.
갱신 손실 방지
더티 쓰기 외에 동시에 실행되는 쓰기 트랜잭션 사이에 발생할 수 있는 충돌이 더 있다.
갱신 손실: 카운터 증가(read-modify-write_와 같이 여러 쓰기가 동시에 수행되는 경우, 시점에 따라 일부 변경사항이 손실될 수 있다.
해결책들은.
1. 원자적 쓰기 연산
데이터베이스에 내장된 원자적 갱신 연산을 사용한다. RDB에서는 다음과 같이 사용한다.
UPDATE counters SET value = value + 1 WHERE key = 'foo';객체를 읽을 때 극 객체에 독점적인 잠금을 획득해서 구현한다. 그래서 갱신이 적용될 때까지 다른 트랜잭션에서 그 객체를 읽지 못하게 한다.
일반적으로는 내부 잠금을 사용하여 구현한다.
2. 명시적인 잠금
애플리케이션 코드에서 명시적으로 객체를 잠근다. 로직을 신중히 짜야한다.
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE ...
FOR UPDATE; /*WHERE 질의에 해당하는 모든 row에 잠금을 건다*/
UPDATE figures SET ...; /*새로운 상태로 갱신한다*/
COMMIT;3. 갱신 손실 자동 감지
잠금 없이 트랜잭션을 병렬로 실행하다가 손실이 감지되면 트랜잭션 관리자가 트랜잭션을 어보트시키고 read-modify-write 주기를 재시도하도록 강제하는 방법이다.
스냅숏 격리와 함께 효율적으로 사용할 수 있고, 애플리케이션 코드에서 데이터베이스 기능을 사용할 필요가 없어진다.
4. Compare-and-set
Compare-and-set 연산은 마지막으로 읽은 후로 변경되지 않았을 때만 갱신을 허용한다.
하지만 스냅숏에 따라 마지막 데이터가 일정하지 않을 수 있으므로 안전하지 않을 수 있다.
UPDATE wiki SET content = 'new content'
WHERE id = 1234 AND content = 'old content'
/*내용이 이미 갱신되어 old content가 아니라면, new content 갱신은 적용되지 않는다.*/5. 충돌 해소와 복제
복제가 적용된 데이터베이스에서 갱신 손실을 막는 것은 다른 차원의 문제다. 여러 노드에 데이터의 복사본이 있어서 데이터가 다른 노드들에서 동시에 변경될 수 있으므로 갱신 손실을 방지하려면 추가 단계가 필요하다.
일반적으로 쓰기가 동시에 실행될 때 한 값에 대해 여러 개의 충돌된 버전(형제, sibling)을 생성하는 것을 허용하고 사후에 애플리케이션 코드나 특별한 데이터 구조를 사용해 충돌을 해소하고 이 버전들을 병합하는 것이다.
쓰기 스큐와 팬텀
경쟁 조건(더티 쓰기, 갱신 손실)을 방지하는 것이 중요해 데이터베이스에서 자동으로 해주든지 잠금이나 원자적 쓰기 연산 같은 수동 안전 장치를 사용해야한다.
이 외에도 쓰기 작업 사이에 잠재적으로 발생할 수 있는 경쟁 조건이 있다. (미묘한 충돌)
<의사 호출 대기 예시>

- 거의 동시에 두 트랜잭션이 시작되었다고 가정
- 데이터베이스에서 스냅숏 격리를 사용하므로 둘 다 2를 반환하여 모두 다음 단계로 진행
- 최소 한 명의 의사가 호출 대기해야한다는 요구사항 위반
- 이러한 현상을 쓰기 스큐(write skew)라고 한다.
쓰기 스큐 특징짓기
- 두 트랜잭션이 두 개의 다른 객체를 갱신하므로 더티 쓰기도 갱신 손실도 아니다. -> 두 트랜잭션이 동시에 실행되어 이상 동작이 나타난 것.
- 쓰기 스큐는 두 트랜잭션이 같은 객체들을 읽어서 그 중 일부를 갱신할 때 나타날 수 있다(다른 트랜잭션은 다른 객체를 갱신한다).
- 여러 객체가 관련되므로 원자적 단일 객체 연산은 도움되지 않는다.
- 추가적인 직렬성 격리가 필요하다
쓰기 스큐를 유발하는 팬텀
- 어떤 트랜잭션에서 실행한 쓰기가 다른 트랜잭션의 검색 질의 결과를 바꾸는 것을 팬텀(Phantom) 이라고 한다.
- 스냅숏 격리는 읽기 전용 질의에서는 팬텀을 회피하지만 읽기 쓰기 트랜잭션에서는 팬텀이 쓰기 스큐의 특히 까다로운 경우를 유발할 수 있다.
충돌 구체화
- 최초의 select시 잠글 수 있는 객체가 없기 때문에 충돌이 일어남 -> 인위적으로 데이터베이스에 잠금 객체를 추가하자!
- 대상 row를 미리 만들고 lock을 건다 -> 트랜잭션의 대상이 되는 특정 범위의 모든 조합에 대해 미리 row를 만들어 둠(ex, 회의실 예약의 경우 다음 6개월 동안에 해당되는 양)
- 예약을 하는 트랜잭션은 테이블에서 원하는 대상 row를 잠글 수 있음(위에서 미리 생성했기 때문)
- 여기서 생성된 row는 단지 동시에 변경되는 것을 막기 위한 잠금의 모음일 뿐이다.(실제 사용되는 데이터가 아님)
- 단점 -> 동시성 제어 메커니즘이 애플리케이션 데이터모델로 새어 나오는 것은 보기 좋지 않음, 다른 대안이 불가능할 때 최후의 수단으로 고려.
직렬성
어떤 경쟁 조건은 '커밋 후 읽기'나 '스냅숏 격리' 수준으로 방지가 되지만 그렇지 않은 것도 있다.
DB의 동시성을 관리하는 방식의 문제점
- 격리 수준은 이해하기 어렵고 데이터베이스마다 그 구현에 일관성이 없음
- 애플리케이션 코드를 보고 특정한 격리 수준에서 해당 코드를 실행하는게 안전한지 알기 어려움. 특히 동시에 일어나는 모든 일을 알지 못할 수도 있는 거대한 애플리케이션이라면 더욱.
- 동시성 문제는 보통 비결정적(간헐적)이라서 테스트하기 어려움(운이 나쁠 때만 문제가 발생)
- 대안은 직렬성 격리 사용. 직렬성 격리는 보통 가장 강력한 격리 수준이라고 여겨짐
- 여러 트랜잭션이 병렬로 실행되더라도, 최종 결과는 동시성 없이 한 번에 하나씩 직렬로 실행될 때와 같도록 보장
직렬성을 제공하는 3가지 기법
- 말 그대로 트랜잭션을 순차적으로 실행하기
- 수십 년 동안 유일한 수단이었던 2단계 잠금
- 직렬성 스냅숏 격리 같은 낙관적 동시성 제어 기법
실제적인 직렬 실행
동시성 문제를 피하는 가장 간단한 방법은 동시성을 완전히 제거하는 것 -> 한 번에 트랜잭션 하나씩만 직렬로 단일 스레드에서 실행하면 됨!
단점 -> 성능...
트랜잭션을 스토어드 프로시저 안에 캡슐화하기
데이터베이스 초창기, 스탤냊ㄱ션이 사용자의 활동 전체 흐름을 포함할 수 있게 하려는 의도가 있었다.
ex. 항공권 예약의 과정(경로 선택, 요금, 좌석 탐색, 일정표, ...) 을 하나의 트랜잭션으로 표현하고 원자적으로 커밋.
-> 이 방법을 구현하기 위해 데이터베이스 트랜잭션이 사용자의 입력을 기다려야한다? -> 매우 느려짐
! 대신에 트랜잭션 코드 전체를 스토어드 프로시저 형태로 데이터베이스에 미리 제출함.
-> 트랜잭션에 필요한 데이터는 모두 메모리에 있고, 스토어드 프로시저는 네트워크나 디스크 I/O 없이 매우 빨리 실행된다고 가정한다.

파티셔닝
각 트랜잭션이 단일 파티션 내에서만 데이터를 읽고 쓰도록 파티셔닝 할 수 있다면, 각 파티션은 다른 파티션과 독립적으로 실행되는 자신만의 트랜잭션 처리 스레드를 가질 수 있다.
이 경우 각 CPU 코어에 각자의 파티션을 할당해서 트랜잭션 처리량을 CPU 코어 개수에 맞춰 선형적으로 확장할 수 있지만,
여러 파티션에 접근해야 하는 트랜잭션이 있다면, 코디네이션 오버헤드가 있으므로 단일 파티션 트랜잭션보다 엄청 느리다.
직렬 실행 요약
- 트랜잭션 직렬 실행은 몇 가지 제약 사항 안에서 직렬성 격리를 획득하는 사용적인 방법이 됐다.
- 든 트랜잭션은 작고 빨라야 한다. 느린 트랜잭션 하나가 모든 트랜잭션 처리를 지연시킬 수 있기 때문이다.
- 활성화된 데이터셋이 메모리에 적재될 수 있는 경우로 사용이 제한된다. 단일 스레드 트랜잭션에서 디스크에 접근한다면 시스템이 매우 느려진다.
- 쓰기 처리량이 단일 CPU 코어에서 처리할 수 있을 정도로 충분히 낮아야 한다. 그렇지 않으면 파티셔닝해야한다.
- 여러 파티션에 걸친 트랜잭션도 쓸 수 있지만 업격한 제한이 있을 수 있다.
2단계 잠금(2PL)
직렬성을 구현하는 데 널리 쓰인 유일한 알고리즘
- 트랜잭션 A가 객체 하나를 읽고 트랜잭션 B가 그 객체에 쓰기를 원한다면 B는 진행하기 전에 A가 커밋되거나 어보트될 때까지 기다려야 한다.
- 트랜잭션 A가 객체에 썼고 트랜잭션 B가 그 객체를 읽기 원한다면 B는 진행하기 전에 A가 커밋되거나 어보트될 때까지 기다려야 한다.
- -> 쓰기 트랜잭션은 다른 쓰기 트랜잭션뿐만 아니라 읽기 트랜잭션도 진행하지 못하게 막고 그 역도 성립.
- vs 스냅숏 격리(읽는 쪽은 결코 쓰는 쪽을 막지 않으며, 쓰는 쪽도 결코 읽는 쪽을 막지 않음)
- 반면 2PL은 직렬성을 제공하므로 갱신 손실과 쓰기 스큐를 포함한 모든 경쟁 조건으로부터 보호해준다.
2단계 잠금 구현
- MySQL, SQL Server 에서 직렬성 격리 수준을 구현하는데 사용된다.
- 잠금은 공유 모드 (shared mode) 나 독점 모드 (exclusive mode) 로 사용될 수 있다.
- 잠금이 아주 많이 사용되므로 교착 상태(두 개의 트랜잭션이 서로 기다리는 것)가 매우 쉽게 발생할 수 있다.
- 데이터베이스는 트랜잭션 사이의 교착 상태를 자동으로 감지하고 트랜잭션 중 하나를 어보트시켜서 다른 트랜잭션들이 진행할 수 있게 한다.
2단계 잠금의 성능
- 가장 큰 약점이 성능
- 잠금을 획득하고 해제하는 오버헤드 때문에 느린것이다.
- 더 중요한 원인은 동시성이 줄어들기 때문(동시성과 성능은 반비례)
서술 잠금
조건에 부합하는 모든 객체에 잠금을 획득하는 것 (아래 예시 조건에 해당하는 모든 객체에 잠금을 획득)
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00'- 서술 잠금은 오래 걸린다.(조건에 부합하는 잠금을 확인하는 데 시간이 오래 걸림)
- 이 때문에 2PL을 지원하는 대부분의 데이터베이스는 실제로는 색인 범위 잠금, 다음 키 잠금을 구현하여 사용한다.
- 진행 중인 트랜잭션들이 획득한 잠금이 많으면 조건에 부합하는 잠금을 확인하는 데 시간이 오래 걸려 잘 동작하지 않는다.
색인 범위 잠금
- 예를 들어, 정오와 오후 1시 사이에 123번 방을 예약하는 것에 대한 서술 잠금을 → 모든 시간 범위에 123번 방을 예약하는 것으로 근사시켜 잠금 실행
- 위의 예시에서 room_id 또는 시간 값에 색인이 걸려있을 것이기에 해당 색인 범위에 lock 을 거는 것임
- 색인 범위 잠금은 서술 잠금 보다 정밀하지 않지만(직렬성을 유지하기 위해 반드시 필요한 것보다 더 큰 범위를 잠글 수도 있음) 오버헤드가 낮기 때문에 좋은 타협안이 된다.
- 범위 잠금을 잡을 수 있는 적합한 색인이 없다면 테이블 전체에 공유 잠금을 잡는 것으로 대체하기도 한다.(성능에는 좋지 않더라도.)
직렬성 스냅숏 격리(SSI)
2PL - 성능이 좋지 않음
직렬성 - 확장이 잘 되지 않음
완화된 격리 수준 - 성능은 좋지만 다양한 경쟁 조건(갱신 손실, 쓰기 스큐, 펜텀)에 취약
모두 만족하는 격리? -> 직렬성 스냅숏 격리(SSI) 알고리즘
비관적 동시성 제어 vs 낙관적 동시성 제어
- 2단계 잠금은 비관적 동시성 제어 메커니즘이다.
- 뭔가 잘못될 가능성이 있으면 뭔가를 하기 전에 상황이 다시 안전해질 때 까지 기다리는게 낫다는 원칙
- 직렬성 스냅숏 격리는 낙관적 동시성 제어 메커니즘이다.
- 뭔가 위험한 상황이 발생할 가능성이 있을 때 트랜잭션을 막는 대신 모든 것이 괜찮아질 거라는 희망을 갖고 계속 진행한다는 뜻
- 트랜잭션이 커밋되기를 원할 때 데이터베이스는 나쁜 상황이 발생했는지 확인함
- 발생했다면 abort 되고 재시도함
- 경쟁이 심하면 abort 비율이 높아지므로 성능 떨어짐
- 예비 용량이 충분하고 트랜잭션 사이의 경쟁이 너무 심하지 않으면, 낙관적 동시성 제어 기법이 성능이 좋은 경향이 있음
- SSI = 스냅숏 격리 + 직렬성 충돌 감지 및 abort 시킬 트랜잭션 결정하는 알고리즘
데이터베이스가 어떻게 질의 결과가 바뀌어 전제가 더 이상 참이 아닌 것을 알 수 있을까? -> 두 가지 상황 고려
1. 오래된 MVCC 읽기 감지 2. 과거의 읽기에 영향을 미치는 쓰기 감지
오래된 MVCC(다중 버전 동시성 제어) 읽기 감지하기

-> 트랜잭션43이 읽기 전용이라면 쓰기 스큐의 위험이 없어보이므로 어보트될 필요는 없다.
-> 트랜잭션42가 어보트될 수 있어 결국에 읽기가 오래되지 않은 것으로 밝혀질 수 있다.
과거의 읽기에 영향을 미치는 쓰기 감지하기

트랜잭션43은 트랜잭션42에게 전에 읽은 데이터가 뒤쳐졌다고 알려주고 트랜잭션42도 트랜잭션43에게 알려준다.
트랜잭션42가 먼저 커밋을 시도해 성공하고 트랜잭션 43이 실행한 쓰기는 트랜잭션 42에 영향을 주지만 아직 트랜잭션43이 커밋되지 않았으므로 그 쓰기 효과는 없다. 그러나 트랜잭션 43이 원할때 충돌되는 쓰기가 이미 있으므로 트랜잭션 43은 어보트돼야 한다.
정리
트랜잭션 - 애플리케이션이 어떤 동시성 문제와 어떤 종류의 하드웨어와 소프트웨어 결함이 존재하지 않는 것처럼 동작할 수 있게 도와주는 추상층이다. 많은 종류의 오류가 간단한 트랜잭션 어보트로 줄어들고 애플리케이션은 재시도만 하면 된다.
트랜잭션이 없다면 복잡한 상호작용을 하는 접근이 데이터베이스에 미치는 영향을 따져보기가 매우 어려워진다.
경쟁 조건의 다양한 예시
- 더티 쓰기 - 아직 커밋되지 않은 데이터를 덮어쓴다.
- 더티 읽기 - 아직 커밋되지 않은 데이터를 읽는다.
- 읽기 스큐 - 클라이언트는 다른 시점에 데이터베이스의 다른 부분을 본다. 스냅숏 격리로 해결(MVCC를 써서 구현)
- 갱신 손실 - 한 트랜잭션이 다른 트랜잭션의 변경을 포함하지 않은 채로 덮어써 내용이 손실된다.
- 쓰기 스큐 - 트랜잭션이 무언가롤 읽고 읽은 값을 기반으로 어떤 결정을 하고 그 결정을 데이터베이스에 쓴다. 그러나 쓰기 시점에 더이상 결정의 전제가 참이지 않다.(직렬성 격리로 해결)
- 팬텀 읽기 - 트랜잭션이 어떤 검색 조건에 부합하는 객체를 읽고 다른 클라이언트가 그 검색 결과에 영향을 주는 쓰기를 실행한다.
완화된 격리 수준은 이런 현상들 중 일부를 막아주지만 일부는 애플리케이션 개발자가 수동으로 처리해야 한다.
직렬성 격리만 이 모든 문제들로부터 보호해준다.
- 트랜잭션을 순서대로 실행하기 - 트랜잭션 실행 시간이 짧고 단일 CPU 코어에서 처리할 수 있을 정도로 처리량이 낮다면 좋다.
- 2단계 잠금 - 직렬성을 구현하는 표준적인 방법이지만 성능이 좋지 않다.
- 직렬성 스냅숏 격리(SSI) - 낙관적 방법을 사용해서 트랜잭션이 차단되지 않고 진행할 수 있게 한다. 트랜잭션이 커밋을 원할 때 트랜잭션을 확인해서 실행이 직렬적이지 않다면 어보트시킨다.
다음에는 분산데이터베이스에서 트랜잭션이 직면한 어려움을 다룬다.
'코딩해 > 기술 블로그(독서)록' 카테고리의 다른 글
| 가상면접 사례로 배우는 대규모 시스템 설계 기초 | 1장 간단 정리 (0) | 2024.03.18 |
|---|---|
| [데이터 중심 애플리케이션 설계] 10장 일괄 처리 | 유닉스 철학 (0) | 2023.06.07 |
| [이펙티브 엔지니어] 2. 학습을 위해 최적화하라 (feat. 회사에서 개발자로 살아남기) (0) | 2022.09.21 |
| [떨림과 울림] (뜬금 없지만) 열역학 법칙 (0) | 2022.09.13 |
| [기술 블로그] 카카오 | 카프카 기반 데이터 스트리밍 플랫폼 (0) | 2022.05.16 |
